
We’ve just entered a very special time of year. Namely the three weeks (from Nov 1st to Thanksgiving) where it's acceptable to talk quotas for the upcoming year.
Broach the topic any earlier, and it’s like touring colleges with a newborn. Any later, and it's a distraction from finishing the year strong. But right now, is just right.
Chorus.ai CEO Roy Raanani posted a whiteboard video on the topic recently. He compared two groups with equal average quota attainment and equal group performance. I've dubbed them:
- Team Summit with a single peak distributed around 80% of quota
- Team Camel with two humps at 60% and 100%
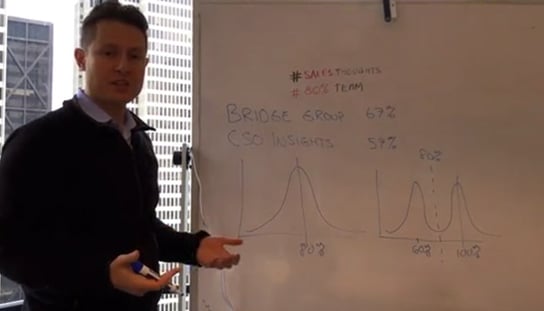
Roy argues Team Summit is preferable. For one, "whenever there is variability [like in Team Camel] it usually means we don't fully understand the process." He continues that reps in the left hump are likely stressed out—as they see how they're underperforming their peers—and ultimately, may face PIP or involuntary termination. I recommend you take a look at the video and comments. It's a great discussion.
As someone who's built a tool for visualizing group performance, I love this topic and wanted to share a few thoughts of my own.
Seek the right-side lean
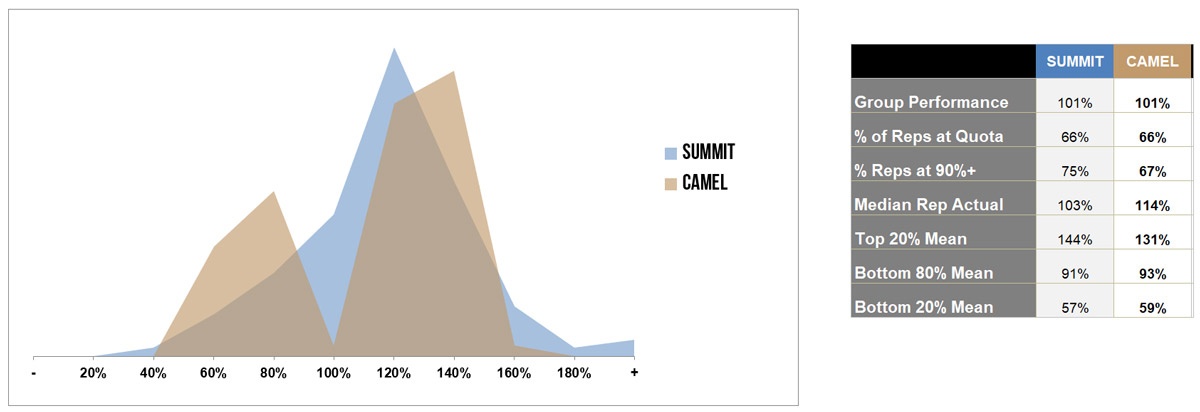
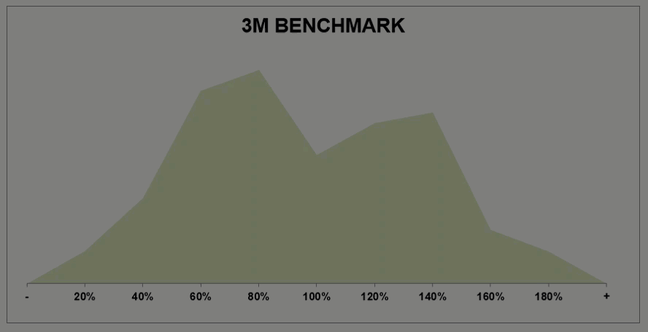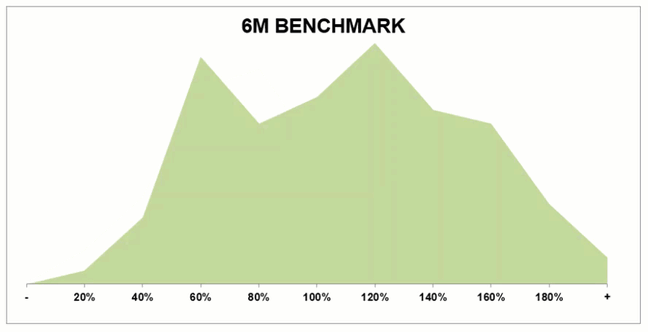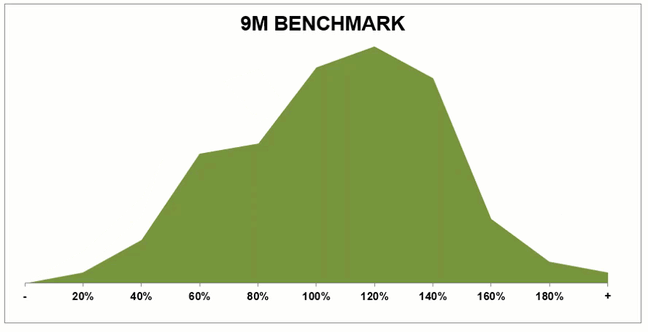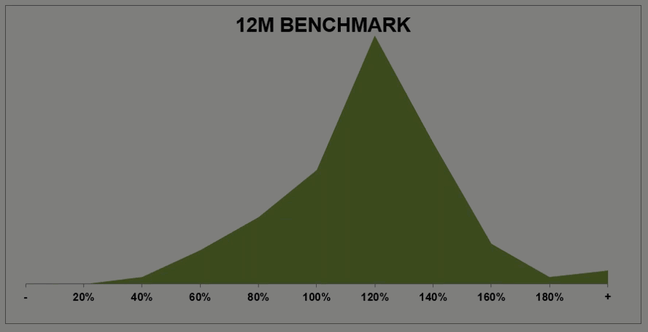
I’ve charted out Roy’s two scenarios and added in performance data assuming the group hits its annual goal.
As you can see, for Team Camel to achieve the same performance level as Team Summit, the right hump needs to be much taller. If the majority of reps are going to hit quota, and ~65% should, then by definition we need more reps on the right side of 100% line.
If your group has two equal sized “humps” you have a problem. It could be inequitable territories, variability in process, uneven coaching, or inconsistent hiring criteria. It’s hard to hit a group number when half the team is missing quota and you’re facing the dual headwinds of low morale and high attrition.
Camels become summits, over time
This second thing I want to share is just how much performance changes between point-in-time snapshots and where teams ultimately end the year. From our data, we’ve detected a general trend from Camels (after 1 or 2 quarters) and towards Summits (after a full 12 months).
A hot hand in Q1 doesn’t automatically mean those reps will have a monster FY. Similarly, a rough front nine doesn’t mean a doomed 140+ round.
Said another way, camels become summits over time. This holds true even for teams with monthly quotas. While April and October may have the same number of working days, you can’t assume they’ll show similar results. Reps are making quota, not widgets. I understand leaders want “predictable” revenue, but the reality is messier than that.
Hiring reps, not robots
My third comment is that I’m not convinced a wider distribution of performance is necessarily a bad thing. It’s tempting to assume we’re Ph.D. Revenue Engineers and that we can squash all the variability in hiring, onboarding, territories, inbound flow, motivation, and so on.
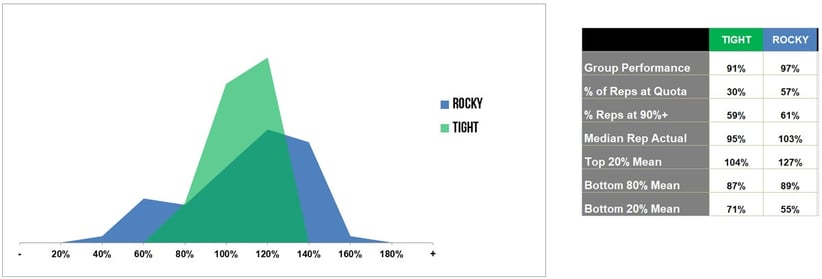
I dug into our data, examined a few dozen groups, and bucketed them as follows:
- Tight Teams with a narrow distribution around quota
versus - Rocky Teams with a wider, more mountainous, distributions
You know what? Rocky Teams outperformed.
One specific area where I think the pendulum has swung too far in controlling variability is hiring profile.
Over-engineering here comes with its own costs. If we work too hard to control the downsides, we invariably limit the upsides. A candidate profile and hiring process that efficiently green-lights Steady Eddys, would likely weed out the occasional Standout Sid or Rockstar Rachel.
I’m not sure where I heard it, but someone recently wrote about “hiring types, not stereotypes.” That seems right on to me. Would love your perspective, too.